
カスタム分類モデルの作成について説明します。
AWSコンソールを使用した説明になります。ポイントになりそうな入力項目のみ説明します。
Model settings
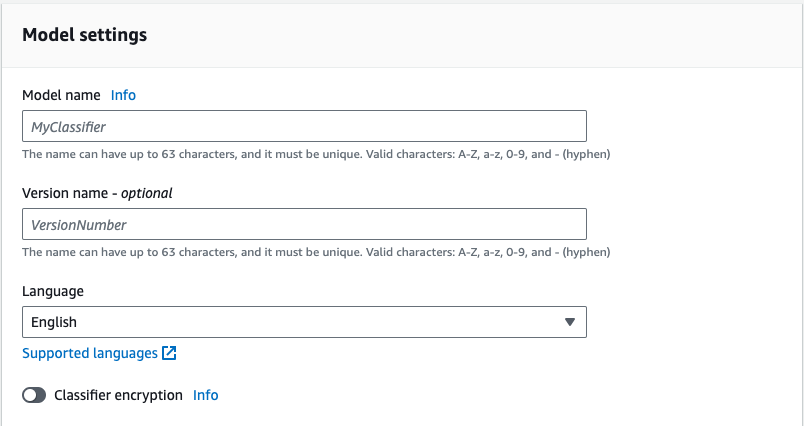
Model name
任意のモデル名を指定します。
Language
JapaneseがないのでEnglishを指定します。
Classifier encryption
(詳しくないのでざっくり説明になります。)
分類モデルが保持するデータを暗号化出来るようです。
暗号化にはKMSが使用でき、KMSは自身のアカウントもしくは自身のアカウント以外のものを指定出来るようです。
Data specifications – Annotation and data format
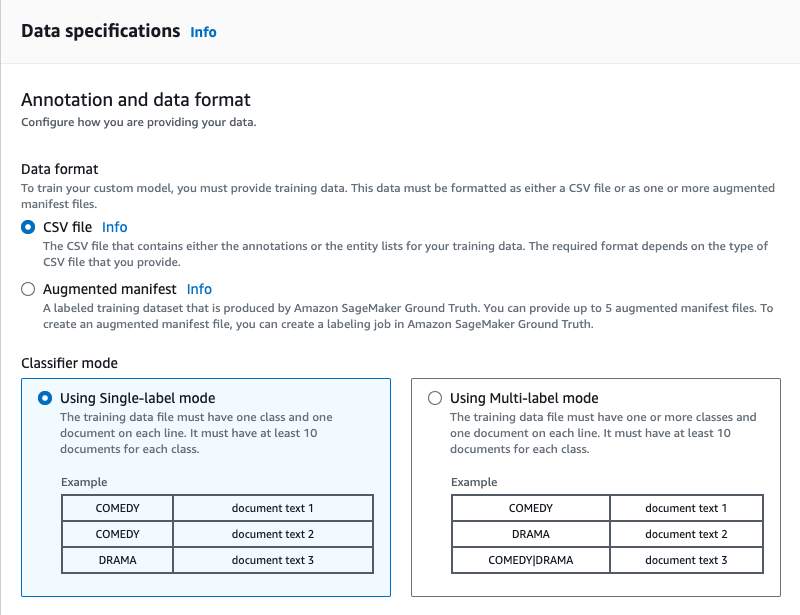
Data format
使用するトレーニングデータのフォーマットを指定します。フォーマットには以下を選択出来ます。
- CSV
- Augmented manifest
CSV
CSVファイル形式のトレーニングデータを使用する場合「CSV」を選択します。
CSVファイル形式のトレーニングデータを作成する方法は以下を参考にして下さい。
Augmented manifest
拡張マニフェストファイル形式のトレーニングデータを使用する場合「Augmented manifest」を選択します。
Classifier mode
使用するトレーニングデータのモードを指定します。
- Using Single-label mode(シングルラベルモード)
- Using Multi-label mode(マルチラベルモード)
Data specifications – DATA
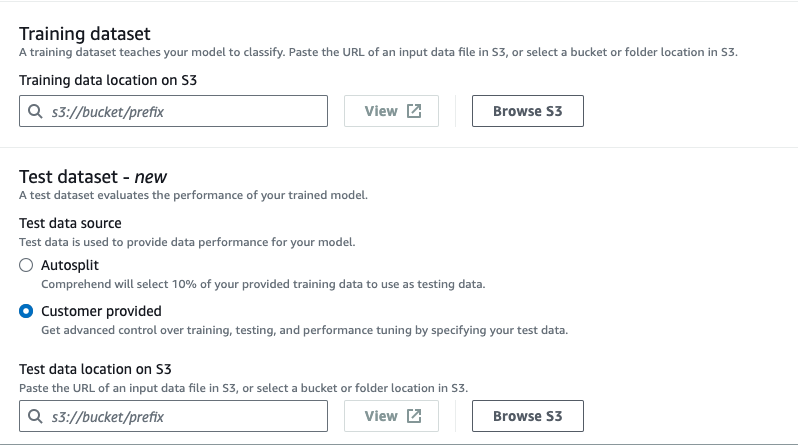
Training dataset
トレーニングデータにCSVファイル形式を使用する場合に指定します。トレーニングデータは予めS3バッケットにアップロードしておき、アップロードしたパスを指定します。
Test dataset
テストデータを指定します。詳細については以下を参考にして下さい。
こだわりがなければ「Autosplit」で良いでしょう。
Output data
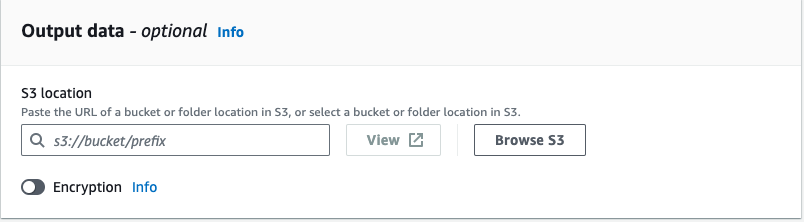
カスタム分類モデルがドキュメントを解析した結果をファイルで出力する際の出力先S3バケットを指定します。
解析結果をファイルへ出力する場合、指定します。
APIを使用したり結果をファイルに出力する必要がない場合は指定する必要はありません。
IAM role
予めロールを作成している場合、「Use an existing IAM role」を指定し、「Role name」をプルダウンから選択します。
新しくロールを作成し、作成したロールを使用する場合、「Create an IAM role」を指定します。権限とロール名を指定しロールを作成します。
その他
こだわりがなければデフォルトで良いと思います。
VPC下でカスタムモデルを使用する場合にVPCを指定したり、タグをつけることも可能です。